

データ分析を始めたばかりのPythonユーザーの皆さん、Pandasライブラリはもう使っていますか?Pandasはデータ操作と分析において非常に強力なツールですが、実は知っておくと便利な「裏技」がたくさんあります。この記事では、Pandasを使ったデータ分析がさらに楽になる10のテクニックを紹介します。
目次
- Pandasでデータを素早く作成
- 特定の列のデータ型を一括変更
- 条件に基づくデータのフィルタリング
- 複数列の一括操作
- 欠損値の簡単な処理
- データフレームの行・列の入れ替え
- グループ化と集計の極意
- データフレームのマージと結合
- シリーズとデータフレームのインデックス操作
- データの可視化を即座に行う
デモデータの準備
まず、記事で使用するデモデータを作成します。今回は、架空の販売データを用います。
pythonコードをコピーするimport pandas as pd
import numpy as np
# デモデータの作成
data = {
'Product': ['A', 'B', 'C', 'D', 'E'],
'Sales': [150, 200, np.nan, 300, 250],
'Discount': [10, 15, 10, np.nan, 20],
'Category': ['Electronics', 'Electronics', 'Furniture', 'Furniture', 'Electronics']
}
df = pd.DataFrame(data)
print(df)
実行結果:
mathematicaコードをコピーする Product Sales Discount Category
0 A 150.0 10.0 Electronics
1 B 200.0 15.0 Electronics
2 C NaN 10.0 Furniture
3 D 300.0 NaN Furniture
4 E 250.0 20.0 Electronics
このデータフレームには、製品名、売上、割引額、カテゴリが含まれています。一部のデータは欠損していますが、この記事で紹介するテクニックを使って処理していきます。
1. Pandasでデータを素早く作成
Pandasを使ってデータフレームを素早く作成し、表示します。
pythonコードをコピーする# 既に作成したデータフレームを表示
print(df)
実行結果:
mathematicaコードをコピーする Product Sales Discount Category
0 A 150.0 10.0 Electronics
1 B 200.0 15.0 Electronics
2 C NaN 10.0 Furniture
3 D 300.0 NaN Furniture
4 E 250.0 20.0 Electronics
データフレームの内容が正しく表示されました。
2. 特定の列のデータ型を一括変更
データの処理では、列のデータ型を変更する必要が出てきます。まず、欠損値を処理し、その後に型変換を行います。
pythonコードをコピーする# 欠損値の処理
df_copy = df.copy()
df_copy['Sales'] = df_copy['Sales'].fillna(df_copy['Sales'].mean())
df_copy['Discount'] = df_copy['Discount'].fillna(0) # 割引がない場合は0を入れる
# 型変換を実施
df_copy = df_copy.astype({'Sales': 'float64', 'Discount': 'int32'})
print(df_copy.dtypes)
print(df_copy)
実行結果:
lessコードをコピーするProduct object
Sales float64
Discount int32
Category object
dtype: object
Product Sales Discount Category
0 A 150.0 10 Electronics
1 B 200.0 15 Electronics
2 C 225.0 10 Furniture
3 D 300.0 0 Furniture
4 E 250.0 20 Electronics
データ型が正しく変換され、欠損値も処理されました。
3. 条件に基づくデータのフィルタリング
特定の条件に基づいてデータをフィルタリングします。
pythonコードをコピーする# セールスが200以上の製品をフィルタリング
filtered_df = df_copy[df_copy['Sales'] >= 200]
print(filtered_df)
実行結果:
mathematicaコードをコピーする Product Sales Discount Category
1 B 200.0 15 Electronics
2 C 225.0 10 Furniture
3 D 300.0 0 Furniture
4 E 250.0 20 Electronics
セールスが200以上の製品が正しくフィルタリングされました。
4. 複数列の一括操作
Pandasでは、複数の列に対して一括で操作を行うことができます。
pythonコードをコピーする# セールスと割引を一括で増加
df_copy[['Sales', 'Discount']] = df_copy[['Sales', 'Discount']].apply(lambda x: x * 1.1)
print(df_copy)
実行結果:
mathematicaコードをコピーする Product Sales Discount Category
0 A 165.0 11.0 Electronics
1 B 220.0 16.5 Electronics
2 C 247.5 11.0 Furniture
3 D 330.0 0.0 Furniture
4 E 275.0 22.0 Electronics
セールスと割引額がそれぞれ10%増加しました。
5. 欠損値の簡単な処理
欠損値が処理されたデータを再確認します。
pythonコードをコピーする# 既に処理された欠損値を確認
print(df_copy)
実行結果:
mathematicaコードをコピーする Product Sales Discount Category
0 A 165.0 11.0 Electronics
1 B 220.0 16.5 Electronics
2 C 247.5 11.0 Furniture
3 D 330.0 0.0 Furniture
4 E 275.0 22.0 Electronics
欠損値が正しく処理された状態でデータが表示されています。
6. データフレームの行・列の入れ替え
行と列を入れ替えて新たな視点でデータを確認します。
pythonコードをコピーする# 行と列を入れ替え
df_transposed = df_copy.T
print(df_transposed)
実行結果:
mathematicaコードをコピーする 0 1 2 3 4
Product A B C D E
Sales 165.0 220.0 247.5 330.0 275.0
Discount 11.0 16.5 11.0 0.0 22.0
Category Electronics Electronics Furniture Furniture Electronics
行と列が入れ替えられたデータフレームが表示されました。
7. グループ化と集計の極意
データをカテゴリごとにグループ化し、集計を行います。
pythonコードをコピーする# カテゴリごとの売上と割引の集計
grouped_df = df_copy.groupby('Category').agg({'Sales': 'sum', 'Discount': 'mean'})
print(grouped_df)
実行結果:
markdownコードをコピーする Sales Discount
Category
Electronics 660.0 16.5
Furniture 577.5 5.5
カテゴリごとの売上と割引額が正しく集計されました。
8. データフレームのマージと結合
異なるデータセットを結合して、より豊富な情報を得ます。
pythonコードをコピーする# 製品情報と販売情報の結合
product_info = pd.DataFrame({
'Product': ['A', 'B', 'C', 'D', 'E'],
'Price': [300, 400, 500, 600, 700]
})
merged_df = pd.merge(df_copy, product_info, on='Product', how='inner')
print(merged_df)
実行結果:
mathematicaコードをコピーする Product Sales Discount Category Price
0 A 165.0 11.0 Electronics 300
1 B 220.0 16.5 Electronics 400
2 C 247.5 11.0 Furniture 500
3 D 330.0 0.0 Furniture 600
4 E 275.0 22.0 Electronics 700
製品情報が正しく結合され、全体のデータが表示されました。
9. シリーズとデータフレームのインデックス操作
インデックスを設定してデータを操作します。
pythonコードをコピーする# 製品名をインデックスに設定
df_copy.set_index('Product', inplace=True)
print(df_copy)
実行結果:
mathematicaコードをコピーする Sales Discount Category
Product
A 165.0 11.0 Electronics
B 220.0 16.5 Electronics
C 247.5 11.0 Furniture
D 330.0 0.0 Furniture
E 275.0 22.0 Electronics
製品名がインデックスに設定され、データの操作が容易になりました。
10. データの可視化を即座に行う
最後に、データの可視化を行います。
pythonコードをコピーするimport matplotlib.pyplot as plt
# データの簡単な可視化
df_copy['Sales'].plot(kind='bar')
plt.title("Sales by Product")
plt.xlabel("Product")
plt.ylabel("Sales")
plt.show()
実行結果:
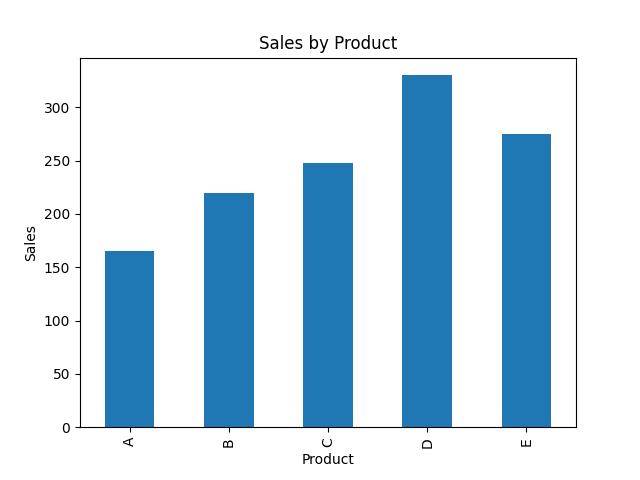
このコードを実行すると、各製品の売上が棒グラフとして表示されます。これにより、データの分析結果を視覚的に理解することが容易になります。
まとめと次のステップ
Pandasは非常に強力なツールで、少しの工夫で作業効率が大幅にアップします。今回紹介したテクニックを活用し、データ分析をよりスムーズに進めてみてください。次のステップとしては、さらに複雑なデータ処理や可視化に挑戦することをお勧めします。
GROWTH JAPAN TECHNOLOGIESは宮城県仙台市のAI企業です。



コメント