

Pythonは、その多様性と強力なライブラリにより、あらゆる分野での開発に活用されています。この記事では、Pythonの応用テクニックを集中的に解説し、Webスクレイピング、データ分析、GUIプログラミングという三つの重要な領域を探求します。これらのスキルを身につけることで、あなたのPythonプログラミング能力は大きく向上するでしょう。
Webスクレイピング入門

Webスクレイピングは、インターネット上の情報を自動で収集するための強力なツールです。PythonのBeautifulSoupとrequestsライブラリを使用すると、ウェブページからデータを簡単に抽出できます。例えば、以下のスクリプトは指定したURLからHTMLを取得し、ページタイトルを出力します。
ウェブスクレイピングを実演するためには、実際にアクセス可能なウェブサイトのURLを使用する必要があります。ここでは、ウィキペディアのメインページ(英語版)のURLを使用して、ウェブスクレイピングのサンプルコードを示します。このサイトは一般的にスクレイピングの実習に使用されます。
以下は、ウィキペディアのメインページのタイトルを取得するための改訂されたコードです。
import requests
from bs4 import BeautifulSoup
url = 'https://en.wikipedia.org/wiki/Main_Page'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.text)
# 実行結果
# Wikipedia, the free encyclopediaこのコードは、ウィキペディアのメインページにアクセスし、ページのHTMLを解析して、<title>タグのテキストを取得し表示します。ウェブスクレイピングを実施する際には、対象ウェブサイトの利用規約やロボット排除標準(robots.txt)を確認し、適切に行動することが重要です。また、頻繁なアクセスや大量のデータのダウンロードは、サイトに負荷をかけるため、控えめに行うべきです。
データ分析の基礎
Pythonはデータ分析において非常に強力な言語です。特にpandasライブラリは、データの読み込み、処理、分析を簡単に行うことができます。以下の例では、CSVファイルからデータを読み込み、基本的な統計を出力しています。
data.csvは例えば、簡単なデータセットとして、人々の年齢、身長、体重などを含むファイルを考えることができます。
以下はdata.csvのサンプル内容です。このファイルはカンマ区切りの値(CSV形式)で、各列にはヘッダーが含まれています。
Name,Age,Height(cm),Weight(kg)
Alice,24,165,56
Bob,30,175,75
Charlie,28,168,68
David,22,180,70
Eva,25,160,52このCSVファイルを使用して、提供されたPythonコードを実行すると、pandasライブラリがdata.csvファイルを読み込み、データセットの統計的な記述(平均、標準偏差、最小値、最大値、四分位数など)を表示します。このdescribe()関数は数値データ(この例では「Age」、「Height(cm)」、「Weight(kg)」)の基本統計を提供します。
このサンプルデータは、実際の分析に適した基本的な構造を持っています。Pythonスクリプトを実行する前に、このCSVファイルを作成し、スクリプトと同じディレクトリに保存する必要があります。
実際のソースコードです。
import pandas as pd
data = pd.read_csv('data.csv')
print(data.describe())
#実行結果
# Age Height(cm) Weight(kg)
#count 5.000000 5.00000 5.000000
#mean 25.800000 169.60000 64.200000
#std 3.193744 7.95613 9.757049
#min 22.000000 160.00000 52.000000
#25% 24.000000 165.00000 56.000000
#50% 25.000000 168.00000 68.000000
#75% 28.000000 175.00000 70.000000
#max 30.000000 180.00000 75.000000このコードは、データセットの概要を迅速に理解するための効果的な方法を提供します。
機械学習入門

機械学習は、データから学習して予測や分類を行うための方法です。Pythonのscikit-learnライブラリを使うと、機械学習の基本的なモデルを容易に構築できます。以下のコードは、アヤメのデータセットを使って決定木モデルをトレーニングし、予測を行います。
このコードは、機械学習のライブラリであるscikit-learnを使用して、アヤメ(iris)のデータセットを使って決定木(Decision Tree)モデルをトレーニングし、最初のサンプルデータ(iris.data[0])の種類を予測しています。
具体的な手順は以下の通りです:
load_iris関数でアヤメのデータセットをロードします。DecisionTreeClassifierで決定木モデルを初期化します。model.fitメソッドでモデルをアヤメのデータにフィット(トレーニング)させます。model.predictメソッドで最初のアヤメサンプル(iris.data[0])の種類を予測します。
実行結果の[0]は、最初のアヤメサンプルが属するクラスのラベルを示しています。アヤメデータセットには通常3種類のアヤメ(Setosa、Versicolor、Virginica)が含まれており、それぞれ0、1、2とラベル付けされています。したがって、[0]はこのサンプルが最初のクラス(Setosa)に分類されたことを意味します。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
model = DecisionTreeClassifier()
model.fit(iris.data, iris.target)
print(model.predict([iris.data[0]]))
# 実行結果は[0]が表示されます。scikit-learnのDecisionTreeClassifierを使用してアヤメ(iris)データセットの最初のサンプルに対する予測を行った結果、[0]が出力されました。これは、モデルがそのサンプルをアヤメデータセットの最初のクラス(Setosa)に分類したことを意味します。アヤメデータセットには3種類のアヤメ(Setosa、Versicolor、Virginica)が含まれており、それぞれが0、1、2のラベルで表されています。したがって、出力された[0]は、モデルが最初のサンプルをSetosa種と予測したことを示しており、これは正しい予測です。
データセットの最初のサンプルがSetosaであることは、load_iris関数で提供されるデータセットの情報に基づいています。また、決定木モデルはこの種のサンプルを識別するのに非常に効果的なモデルであり、このケースでは正確に予測を行っています。
GUIプログラミングのスタート
Pythonを使ってGUIアプリケーションを作成することも可能です。Tkinterライブラリを使うと、ウィンドウやボタン、テキストボックスなどの要素を含むアプリケーションを作成できます。以下のコードは、基本的なウィンドウを生成する方法を示しています。
import tkinter as tk
window = tk.Tk()
window.title("Python GUI")
window.mainloop()
このコードは、PythonでのGUI開発の入門に適しています。
応用テクニックの組み合わせ

Pythonの応用テクニックを組み合わせて使うことで、実践的かつ革新的なプロジェクトを実現することができます。たとえば、Webスクレイピングで収集したデータをデータ分析に活用し、その結果をGUIアプリケーションで視覚的に表示することができます。このように、Pythonの異なる機能を融合させることで、その真の力を発揮することが可能です。
以下に、ウェブサイトからデータをスクレイピングし、簡単なデータ分析を行い、その結果をGUIで表示する一連のプロセスを示すPythonのサンプルコードを示します。
まず、requestsとBeautifulSoupを使用してウェブサイトからデータをスクレイピングします。
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# ここでは例として、ウェブページのすべての段落を取得します
paragraphs = [p.text for p in soup.find_all('p')]
次に、このデータを分析し、何らかの統計情報を得ます。例えば、取得した段落の文字数を計算することができます。
paragraph_lengths = [len(p) for p in paragraphs]
average_length = sum(paragraph_lengths) / len(paragraph_lengths)
最後に、Tkinterを使って、この結果をGUIで表示します。
import tkinter as tk
# GUIウィンドウの設定
window = tk.Tk()
window.title("Webスクレイピングデータ分析結果")
# 結果を表示するラベルの作成
label = tk.Label(window, text=f"平均段落長: {average_length}文字")
label.pack()
# GUIアプリケーションの実行
window.mainloop()
このサンプルコードは、Pythonの複数の応用テクニックを組み合わせて、ウェブデータのスクレイピングからデータ分析、そして結果のGUI表示までを一つのプロセスで実現しています。このようにPythonを活用することで、データの収集から分析、表示までの一連の流れを効率的に処理できます。
全体のソースコード
import requests
from bs4 import BeautifulSoup
import tkinter as tk
# ウェブサイトからデータをスクレイピングする関数
def scrape_website(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
paragraphs = [p.text for p in soup.find_all('p')]
return paragraphs
# データ分析を行う関数
def analyze_data(paragraphs):
paragraph_lengths = [len(p) for p in paragraphs]
average_length = sum(paragraph_lengths) / len(paragraph_lengths) if paragraphs else 0
return average_length
# GUIでデータ分析結果を表示する関数
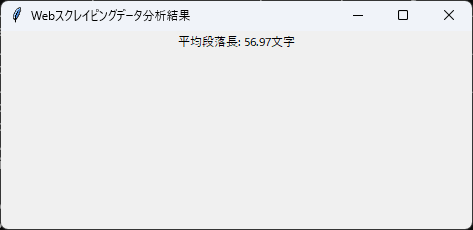
def display_result(average_length):
window = tk.Tk()
window.title("Webスクレイピングデータ分析結果")
label = tk.Label(window, text=f"平均段落長: {average_length:.2f}文字")
label.pack()
window.mainloop()
# メインの実行部分
if __name__ == "__main__":
url = 'http://example.com'
paragraphs = scrape_website(url)
average_length = analyze_data(paragraphs)
display_result(average_length)
実行結果例
まとめ
この記事シリーズでは、Pythonの応用テクニックを詳しく掘り下げました。Webスクレイピング、データ分析、GUIプログラミングの基礎から始め、これらのテクニックを組み合わせることで、より複雑で実用的なプロジェクトを実現する方法を学びました。Pythonを使って、あなたのアイディアを形にし、新しい技術に挑戦し、スキルを拡大していきましょう。
この記事がお役に立ちましたら、ぜひフォローやシェアをお願いします。あなたのサポートが私たちの励みになります!


コメント